Data Lake: un data lake es un repositorio centralizado diseñado para almacenar, procesar y proteger grandes cantidades de datos estructurados, semiestructurados o no estructurados. Puede almacenar datos en su formato nativo y procesar cualquier variedad de datos, sin importar los límites de tamaño.
DataWarehouse: un almacén de datos o repositorio de datos es una colección de datos estructurados orientada a un determinado ámbito, integrado, no volátil y variable en el tiempo, que ayuda a la toma de decisiones.
Infraestructura "modelo" de un Data Lake.

Fuente: Video de RD

DataLakeHouse: es una arquitectura de datos moderna que crea una plataforma única mediante la combinación de los beneficios clave de los data lakes (grandes repositorios de datos sin procesar en su forma original) y los almacenes de datos (conjuntos organizados de datos estructurados).
Proveedores líderes (históricos) en data lakes:
Actualmente, cada plataforma (Cloud) tiene sus herramientas:

Opciones de Data Lake Open Source:

AirByte: extraccion de datos
PostgreSQL / BigQuery
Airflow: herramienta de orquestacion procesos
DBT: para estructurar procesos de transformacion de datos.
Superset: idem PowerBI
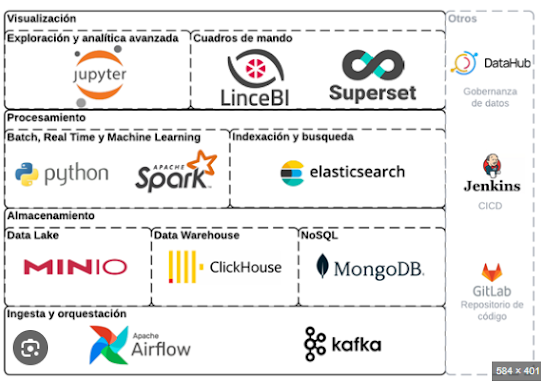
Ingeniería de datos

Carga de datos (en tiempo real)
Spark
kafka
Traditional-structured Data (herramientas que no requieren saber programar)
Azure Data Factory
AWS Glue
Google Dataflow
IBM Infosphere
Unstructured Data (permiten tomar un documento y extraer información)
Spark (requiere programacion, Python)
nifi
Data Marurity Index (DMI)
Niveles de madurez en el uso de datos - Data Marurity Index (DMI)
Se puede bajar PDF de evaluación aquí.
** Modelos de recomentacion (viste esa pelicula?)
Advanced Analytics
El análisis avanzado es el proceso de utilizar técnicas complejas de machine learning (ML) y visualización para obtener información de datos más allá de la inteligencia empresarial tradicional. Las organizaciones modernas recopilan grandes volúmenes de datos y los analizan para descubrir patrones y tendencias ocultos. Utilizan la información para mejorar la eficiencia de los procesos empresariales y la satisfacción del cliente. Con el análisis avanzado, puede ir un paso más allá y utilizar los datos para la toma de decisiones futuras y en tiempo real. Las técnicas de análisis avanzado también extraen conclusiones a partir de datos no estructurados, como los comentarios o las imágenes de las redes sociales. Pueden ayudar a su organización a resolver problemas complejos de manera más eficiente. Los avances en la computación en la nube y el almacenamiento de datos han hecho que el análisis avanzado sea más asequible y accesible para todas las organizaciones.
Advanced Analytics es poder dialogar con los datos. Es la combinación de Data Mining con BI. Es detectar patrones dentro de mi información.
Si bien las tecnologias avanzan hacia el low code o no code, surgen estas otras especialidades.
Machine Learning Engeneer
Un Professional Machine Learning Engineer crea, evalúa, produce y optimiza modelos de AA (Aprenidzaje Automático) mediante las tecnologías de Cloud y el conocimiento de modelos y técnicas comprobados. El ML Engineer controla conjuntos de datos grandes y complejos, y crea código repetible y reutilizable.

MLOps (Machine Learning Operations)
MLOps tiene como objetivo implementar y mantener modelos de aprendizaje automático en producción de manera confiable y eficiente.
mlflow (herramienta Open Source de databricks)
Azure Machine Learning (Microsoft)
Amazon SageMaker (Amazon)
Vertex AI (Google)
Gobierno de Datos
Data Hub: es una herramienta de codigo libre. Sirve para armar un catdefinir un Catálogo y un Diccionario de datos, definir que es cada dato y para qué se usa. Otras similares son PureView (Microsoft), Unity (DataBricks),
Conceptos varios:
Data Stewards (tecnico): es el guardián de las políticas de datos dentro de la organización. Por tanto, debe definir, implementar y mantener las reglas y estándares que rigen el uso de los datos para que sean fiables y se les dé un uso correcto. Calidad de los datos. Estos deben estar completos y ser coherentes
Data Owners (negocio): los propietarios de datos tienen responsabilidades específicas relacionadas con el dominio, incluida la seguridad de los datos, el control de acceso y la toma de decisiones dentro de sus áreas de datos asignadas.
Auditoria: identificar patrones y tendencias en los datos para detectar posibles fraudes y errores, así como para mejorar la eficiencia y eficacia del proceso de auditoría y también puede ayudar a las empresas a identificar nuevas oportunidades de negocio y a mejorar la toma de decisiones.
Data Lineage (trazabilidad): el linaje de datos es el proceso de rastrear el flujo de datos a lo largo del tiempo, facilitando la comprensión de dónde se han originado los datos, cómo han cambiado y su destino final dentro de la canalización de datos.
Data Quality: se refiere al grado en que los datos cumplen con los estándares y requisitos establecidos para su uso en la empresa.
Data LifeCycle: el ciclo de vida de los macrodatos consta de cuatro fases: recopilación de datos, almacenamiento de datos, análisis de datos y creación de conocimiento
I
No hay comentarios:
Publicar un comentario